

PDF形式のデータ、便利そうで意外と扱いづらいと感じたことはありませんか?特に、スキャンしたPDFや画像形式のファイルでは、必要な情報を編集したり検索したりするのが大変ですよね。これが原因で、時間がかかったり手作業でミスが発生することも多いものです。
そこでおすすめしたいのが「OCR技術の活用」です。OCRを使えば、画像やスキャンPDFを瞬時に文字データに変換し、編集や検索が可能になります。AIを活用した最新のOCRは、高精度かつ手書き文字にも対応しており、業務効率化に大きく貢献します。
もし「PDFをもっと効率よく活用したい!」とお考えなら、この記事で紹介する方法をぜひ試してみてください。あなたの業務を劇的に変えるヒントが見つかるはずです。
PDF化だけでは不十分!OCR化が必要な理由
PDFは多くの場面で役立つフォーマットですが、スキャンした文書や画像形式のPDFがデータ活用の壁になることも少なくありません。そこで注目されるのがOCR技術です。本記事では、PDFの課題とOCRによる解決策について詳しく解説します。
PDFの利便性と限界
PDF(Portable Document Format)は、異なるデバイスや環境でも一貫したレイアウトで情報を閲覧できる便利なファイル形式です。契約書や請求書、パンフレットなど、ビジネスから日常生活まで幅広い場面で使用されています。その利便性から、企業内でもPDFを標準的な書類フォーマットとして採用しているケースが少なくありません。
しかし、PDFには課題もあります。データを参照するだけであれば問題ありませんが、編集や加工が必要な場合、専用のソフトウェアが必要となります。また、PDF内の情報をエクセルやデータベースに移行する場合、手作業でのコピー&ペーストが必要になり、これが業務効率の低下を招く要因となるのです。手作業では時間がかかるだけでなく、入力ミスのリスクも避けられません。
さらに、スキャンしたPDFや画像形式のPDFでは、文字として認識されていないことが多く、従来のツールではデータの抽出が困難です。このため、多くの現場で「PDFは見るだけのファイル」として扱われ、データ活用が進まない要因となっています。
OCRの進化がもたらす変革
OCR(Optical Character Recognition)は、画像やPDFに含まれる文字をデジタルデータとして認識・変換する技術です。スキャンした書類や画像形式のPDFなど、従来は「読むだけ」だったデータを、編集可能なテキストや表形式データとして活用できるようにします。
この技術は、AIや機械学習の進化により大きく向上しています。手書き文字や複雑なフォントも高精度で認識できるようになり、ビジネスのさまざまな場面で活用されています。例えば、請求書や領収書のデータ化、契約書からの重要情報抽出などが挙げられます。
OCRの導入により、手作業でのデータ入力が不要になり、業務効率化だけでなく、ヒューマンエラーの削減も期待できます。
PDFの課題を解決するOCR技術
PDFは情報を正確に伝えるために広く利用されるフォーマット、というのは前述した通りです。しかし、「テキストのデジタル化」という作業においてはそのままでは十分な解決策になりません。特にスキャンデータや画像から生成されたPDFの場合、文字は単なる画像として扱われ、編集や検索ができない状態になっています。このような「非構造化データ」は、単純なツールや操作では扱いにくいのが現実です。
たとえば、会議の議事録を手書きし、それを写真で保存している場合、議事録をデジタルデータとして活用するには、手作業で転記作業をしなければならなりません。この作業は非常に時間がかかり、正確性にも課題があります。また、大量の書類を処理する場合はさらに問題が深刻化します。
ここで重要になるのが、先ほど説明したOCR技術の活用です。OCRは、画像データとして埋め込まれた文字をデジタル化し、検索や編集が可能な形式に変換します。特に最近のOCRツールは、AIの進化により手書き文字や特殊なフォント、複雑なレイアウトにも対応可能になっています。これにより、PDFで提供された情報を有効活用するためのハードルが大幅に下がったのです。
初心者でも簡単!PDFをOCR化して業務効率化を実現する手順
LightPDFでOCR化する方法
「LightPDF」というフリーのOCRサービスを使ってみます。LightPDFはPDFの編集などが行えるツールですが、OCR機能も備わっています。
上記URLからサイトにアクセスできます。TOPページが開いたら、メニューからOCRを選択すると、ファイルの選択画面になるので、PDFファイルを選択した後に出力先を選択します。デフォルトではWord形式になっています。最後に「OCR」ボタンを押すと、デジタル化されてWordファイルがダウンロードできるようになります。
読み込み元PDF
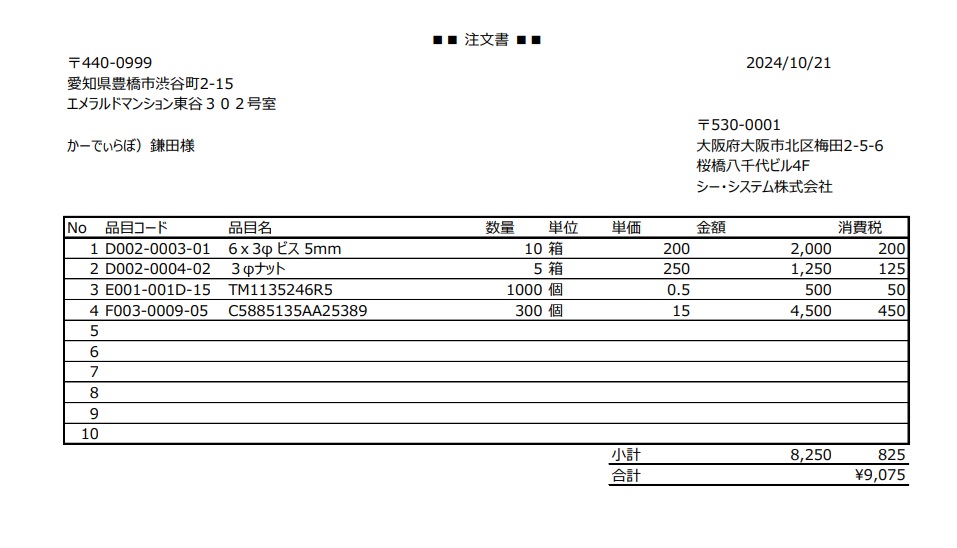
こちらのPDFファイルの明細部に記載された内容を、データ活用したいと考えています。
変換後のWordファイル
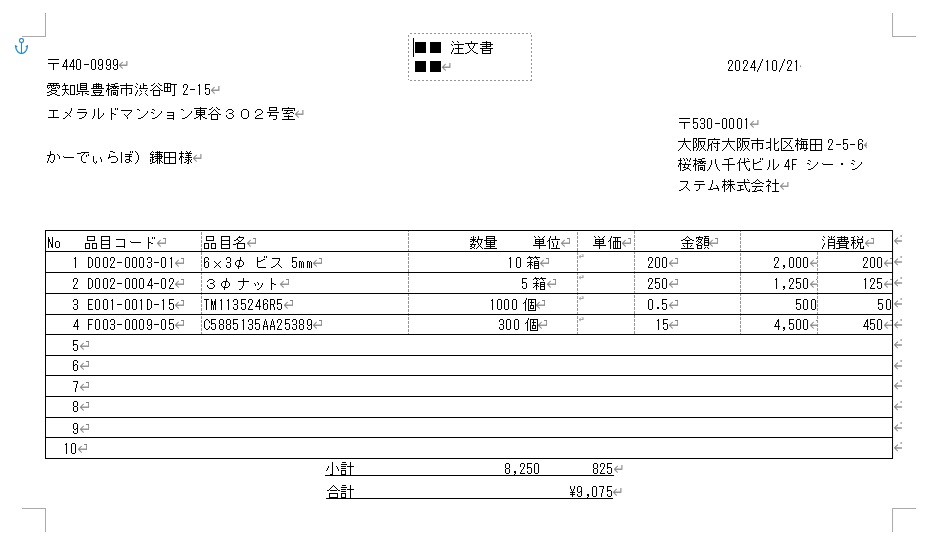
このように非常にカンタンにPDFファイルからWordファイルへ変換することができました。文字認識も正しく行われています。ただ、表組のレイアウトが崩れてしまっており、これを正しいレイアウトに修正するのは、少し手間がかかりそうです。また、明細部以外の情報も付与されており、ヘッダー部などの余分な情報を削除する手間も残ってしまいました。

AI JIMY PaperbotでOCR化する方法
AI JIMY Paperbotは、シーシステムが提供しているOCRソフトウェアです。OCRソフトウェアですが、RPA機能も兼ね備えており、OCRで抽出したデジタルデータをシームレスにRPAと連携でき、業務効率化の非常に頼もしいツールです。
AI JIMY Paperbotでテキスト化するには、次の手順で行います。
①ワークフローの新規作成。
②取り込み:PDFファイル(や画像ファイル)の取り込み方法の設定。
③仕分け:種類が複数ある場合に、それぞれに応じた読み込み方法を指定できます。
④文字認識:帳票毎にどこをどのように読取るか指定します。
⑤データ出力:読み取った結果をCSVファイル等に自動的に出力します。
⑥RPA:読み取ったデータを、別のシステムに転記等を自動化します。
操作手順としては少し多いですが、それぞれの設定の仕方は直感的にわかりやすくなっており、操作で迷うことはありません。また、帳票が1種類しか無い場合は③の仕分けはスキップできますし、RPA連携がなければ⑥のRPAもスキップできます。
先ほどと同じPDFファイルをAI JIMY Paperbotで処理し、Excelに転記した結果は以下になります。
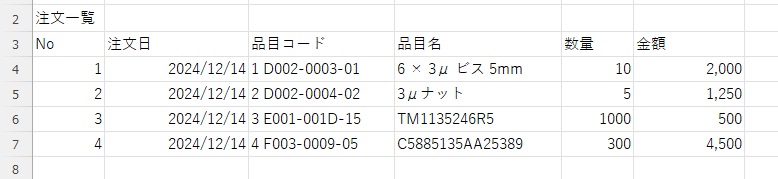
文字認識がしっかりとされていることはもちろん、表組も完璧に再現されており、手直しすることなくこのままデータ活用できます。
また、必要な明細部だけを転記できていることにも注目です。今回必要としたのは明細部だけでしたので、あえてヘッダー部の転記処理はしておりません。このように「痒い所に手が届く」ツールが、AI JIMY Paperbotです。

AI JIMY Paperbotを利用するメリット
OCRに生成AIとRPAを搭載 一つのツールでデータ入力作業を完結
画像の取り込みから取引先ごとの仕分け、手書き文字の認識、テキストデータの出力、業務システムへのデータ入力まで、一連の作業をAI JIMY Paperbotひとつで自動化できます。
無料で誰でもカンタンに使用可能
AI JIMY Paperbotは特別な技術知識は不要で、マウスだけの直感的な操作が可能です。RPAツールとの連携や専門知識が必要なAPIなどの開発作業は必要ありません。無料で利用開始できますので、カンタンに試すことができます。
自動でファイル名を変換できるリネーム機能
リアルタイム処理を行い、任意で電子帳簿保存法の改正にも対応したファイル名に自動で変換可能です。
AI類似変換で社内のマスタと連携し、文字認識が向上
日本語の認識は、手書きも含めてかなり高い精度で変換できます。間違いやすい商品名などの固有名詞は、あらかじめAI JIMY Paperbotに登録しておくことでさらに認識率が向上します。
多様な業務で活用
さまざまな業務で使用が可能です。FAXの受注入力、請求書の集計、手書きアンケートや申込書のデータ入力、作業日報のデジタルデータ化など多岐にわたる業務プロセスをサポートします。
OCR化でPDFが即戦力に!検索・編集・リスト作成の具体的な活用法
OCRで可能になる3つのこと
こちらでは、OCRによるデジタル化で可能になる「検索」「編集」「リスト作成」の3つに絞って、具体的な活用方法を示していきます。
検索について
OCRによりPDF内の文字情報がデジタル化されると、文書全体から瞬時にキーワードを検索できるようになります。これにより、必要な情報を探すためにページをめくる手間が大幅に削減されます。例えば、過去の契約書から特定の条項を確認する場合、数百ページに及ぶ資料でも秒単位で目的の情報を見つけることが可能です。
また、会議議事録をOCRでデジタル化しておけば、特定の案件や発言者の記録を検索しやすくなります。これにより、意思決定の迅速化や、後追い調査の効率向上が実現します。さらに、顧客対応では、過去の取引履歴や問い合わせ内容を瞬時に把握でき、スムーズな対応が可能となります。検索機能は、業務のスピードと正確性を向上させる大きな武器になります。
編集機能について
OCRでPDF内の文字を編集可能なデジタルデータに変換すると、内容の修正や追加が容易になります。例えば、請求書や契約書の一部情報を更新する場合、元データを一から作り直す必要がなく、必要箇所だけを効率よく修正できます。これにより、書類の再作成にかかる時間と労力を大幅に削減できます。
また、PDF内の情報をExcelやWordに移行することでカスタマイズ可能になるため、報告書の作成やデータ分析にも活用できます。例えば、複数の支店から集めた販売報告書をOCRでデジタル化し、一つのExcelファイルに統一することで、データが利用しやすくなり作業効率が向上します。
リスト作成機能について
OCRによってPDF内のデータをデジタル化すると、必要な情報を抽出してリスト形式にまとめることが可能になります。例えば、スキャンされた名刺データをOCRで読み取り、名前や連絡先をエクセルで整理すれば、顧客リストを自動的に作成できます。これにより、営業活動やマーケティング施策での活用がスピーディーに行えます。
また、請求書や注文書から商品名や金額、日付を抽出してリスト化することで、経理業務や在庫管理が効率化されます。特に、大量の書類を手作業で整理する負担を削減でき、ヒューマンエラーも防げます。リスト作成により、データ分析や報告書作成など、次の業務工程もスムーズに進行します。
具体的な業務シナリオ
実際の業務に即したシナリオを通して、OCRの活用イメージを具体化してみます。ここでは、事務職と営業職を想定したシナリオを考えてみました。
事務職の場合
ある会社では、毎月数百枚におよぶ請求書の処理を行っており、これまでは紙やPDFの請求書を目視で確認し、手作業でエクセルに顧客名、金額、支払い期日を入力していました。しかし、この業務にOCRを導入したことで、大幅な効率化が実現しました。
OCRを使用してスキャンした請求書から顧客名や金額、支払い期日を自動的に抽出し、Excel形式で整理することで、未払い金額を一覧化しやすくなりました。これにより、支払い状況の確認が迅速かつ正確に行えるようになったのです。
さらに、デジタル化されたデータはカンタンに検索が行えるため、特定の顧客名や金額を瞬時に見つけることが可能になりました。たとえば、「A社の未払い状況を教えてほしい」という依頼にも、短時間で対応できます。このように、OCRの活用により業務スピードと正確性が向上し、事務作業の負担が大幅に軽減されました。
営業職の場合
営業日報は、訪問先で得た情報を社内で共有する重要な仕組みです。これまでは、訪問後に手書きでメモを取り、帰社後にSFA(営業支援システム)などのデータベースへ入力していました。この手法では、入力ミスや記録漏れが発生しやすく、営業活動の振り返りや次回訪問準備に多くの時間を要するという課題がありました。
この問題を解決するため、OCRを導入しました。訪問後、手書きのメモをスマートフォンで撮影し、OCRツールを使用して顧客名、訪問日時、要件、次回対応内容を自動的にデータベースへ登録します。
これにより、営業チームは顧客情報を迅速に検索でき、次回訪問時に必要な情報を即座に把握可能となりました。また、訪問履歴を基に進捗状況を確認しやすくなり、報告書作成やチーム内の情報共有も円滑化。OCRの活用によって営業活動が効率化され、より戦略的な取り組みが可能となりました。

PDFのOCR化で失敗しないためのコツ!認識精度向上と注意点を解説
OCR化の課題を認識する
OCRは、スキャンした書類や画像から文字を抽出し、デジタルデータ化する便利な技術ですが、すべてのPDFや画像に対して完璧な結果が得られるわけではありません。たとえば、解像度の低い画像や背景にノイズが多い場合、認識精度が大幅に低下することがあります。また、特殊なフォントや複数言語が混在している書類も誤認識が発生しやすいです。そのため、OCRを導入する際は対象となるPDFや画像の特性を事前に確認することが重要です。
OCR認識精度を向上させるコツ
OCRを効果的に活用するためには、いくつかのポイントを押さえることで認識精度を大幅に向上させることが可能です。以下にその具体的なコツを紹介します。
1. 高解像度の画像を使用する
OCRは、画像内の文字を解析して認識するため、解像度が低い画像では精度が下がります。最低でも300dpi(dots per inch)の解像度を目安にスキャンすることで、文字の輪郭がはっきりし、誤認識を防ぐことができます。
2. 明るさとコントラストを調整する
画像が暗かったり、背景が文字と似た色合いの場合、OCRは文字を正確に認識しにくくなります。スキャン後に画像編集ツールを使って明るさやコントラストを調整し、文字が鮮明に見える状態にすることが効果的です。
3. 適切なフォントとレイアウト
印刷物の場合、シンプルなフォントや均等な文字間隔が認識しやすいですが、手書き文字や複雑なフォント、縦書きや横書きが混在するレイアウトは、事前に整理しておくと精度向上につながります。また、手書き文字はなるべく丁寧に書くようにしましょう。
4. 特定のOCRツールを選ぶ
OCRツールにはそれぞれ得意分野があります。たとえば、手書き文字の認識に強いものや、多言語対応に特化したものを選ぶと、認識精度が向上します。無料のツールではなく、有料版や業務用のツールを検討するのも一つの手段です。
5. 事前に画像を加工する
画像の不要な部分をトリミングしたり、傾きがある場合は補正することで、OCRエンジンが文字を正確に捉えやすくなります。また、背景ノイズを除去する専用の画像処理ソフトを活用するのも効果的です。
これらのコツを取り入れることで、OCRの認識精度を向上させ、データ化の効率を最大限に引き上げることができます。事前の準備をしっかり行い、適切なツールや手法を組み合わせることが成功の鍵です。
OCR利用時の注意点
セキュリティとプライバシー
OCRを利用する際は、データの取り扱いに注意が必要です。特に、請求書や契約書などの機密情報を含む書類を扱う場合、ツールのセキュリティ対策を確認しましょう。オンラインOCRサービスでは、アップロードしたデータがどのように保存・処理されるかを確認し、情報漏洩のリスクを防ぐ必要があります。また、社内で利用する場合も、アクセス権限の管理を徹底し、不正利用を防止することが重要です。
誤認識のリスク
OCRは万能ではなく、フォントやレイアウト、解像度の影響を受けて誤認識が発生する可能性があります。たとえば、「0」と「O」、「1」と「I」などが間違って認識されるケースが典型例です。これにより、請求金額や取引先名の誤記が発生する恐れがあります。重要なデータを扱う場合は、OCR結果を必ず確認し、誤認識を修正するプロセスを設けることが安全策となります。
言語設定の確認
OCRツールを使用する際は、対象となる言語の設定が正しいかを確認することが重要です。設定が適切でない場合、文字の認識精度が著しく低下し、結果としてデータの品質に影響を与える可能性があります。特に多言語対応が必要な場合、ツールが使用する言語を切り替えられるか、特定の言語に強いツールを選定することが求められます。

まとめ
PDFは情報を共有・保存する上で非常に便利なフォーマットですが、そのままでは内部のテキストを編集したり活用したりするのが難しい場合があります。特にスキャンしたPDFや画像形式のPDFでは、文字情報が単なる画像データとして扱われるため、利用には限界があります。
OCRは、こうしたPDFから文字をデジタル化し、編集や検索を可能にする強力なツールです。ただし、最大限に活用するためには、適切なツール選びや設定が重要です。認識精度を向上させるコツや、使用時の注意点を押さえることで、業務効率化やデータ活用の効果を高めることができます。
AI JIMY Paperbotは、AI OCR技術を活用し、手書き文字の高精度な読み取りが可能です。また、RPAとの連携により、さまざまな出力形式にも対応できる優れたツールで、幅広い業務に活用することができます。


