

まず、PDFのメリットとは何でしょうか?一番大きなメリットは、どの環境でも印刷レイアウトが崩れないことです。ただし、これは印刷を前提とした場合です。通常の業務におけるPDFのメリットは、データの整合性を保てる点にあります。
もちろん、PDFを編集できるソフトもありますが、業務利用での利用者はそれほど多くありません。そのためPDFファイルは編集が難しく、整合性が担保できるのです。特にステークホルダーとのファイルのやり取りでは、誤って上書きされることを防ぐため、PDF形式にするのが一般的です。
しかし、ステークホルダーから送られてきたPDFを業務で活用しようとすると、いろいろと手間がかかることがあります。
- オフィスソフトで生成されたPDFではなく、単にスキャン画像がPDF化されている、中身が画像問題
- PDFのレイアウトによってはコピー&ペーストがうまくいかない、 変な表組入ってる問題 など
ここでは、そうしたPDFの内容を如何に効率的にデータとして活用するかについて解説いたします。
PDFをエクセルに変換するメリット
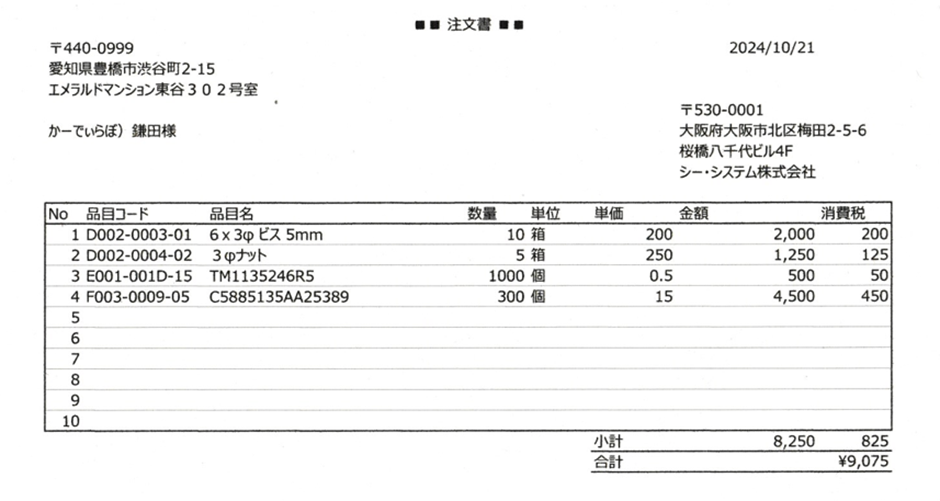
まず、試しにPDFデータをエクセルに変換してみましょう。ここでは、下記のような注文書のPDFデータを例に、明細部分だけをエクセルに変換する方法を紹介します。
エクセル化のメリット
- PDFと同じレイアウト、同じ並びでデータが見えるため、エクセル化された際に正しく変換されているか簡単に確認できる
- 数量や金額、小計、合計などの計算ミスがないか数式を入れることで、確認が容易
- データが構造化されるため、RPAなどでの処理が容易になる
エクセル化することで、こうした多くのメリットが得られます。
では、どのようにエクセル化すれば良いのでしょうか?具体的な方法を見ていきましょう。
手動でPDFからエクセルに変換する方法
PDFを手動でエクセルに変換するには、必要な項目をPDFから1つずつコピーして、エクセルに貼り付けます。これを必要なすべての項目に対して繰り返していく方法です。
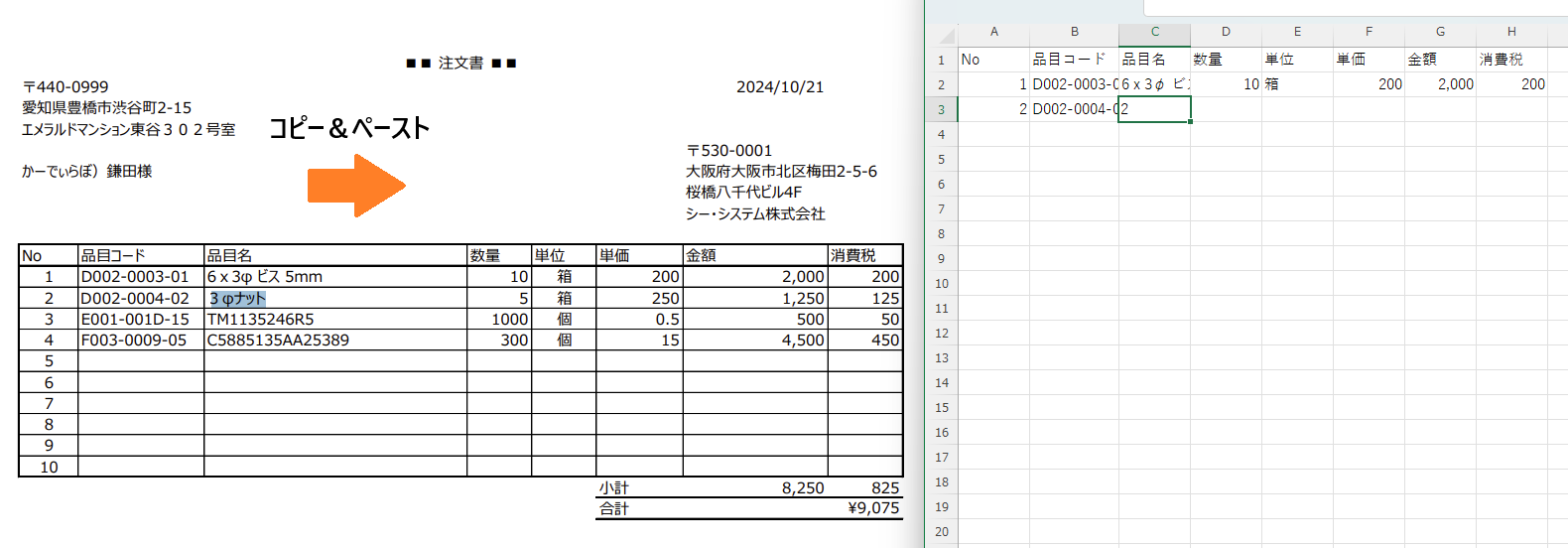
非常に手間のかかる作業ですよね。手入力すると入力ミスのリスクが高くなりますし、それを防ぐにはコピー&ペーストが一番確実ですが、効率が非常に悪いです。この例ではコピーする項目数が少ないため手作業も可能かもしれませんが、項目が多くなればなるほど大変になります。
また、作業が長時間にわたると途中で休憩を入れたくなりますが、再開時にどこまで進んだかがわからなくなり、貼り付ける位置がずれてしまうこともあります。このように、手動で行うとどうしてもミスが発生しやすくなります。
Microsoft Officeツールを使ったエクセル変換
手動での作業は大変でした。しかし実は、エクセルから直接PDFを読み込むことができるのをご存知でしたか?以下の手順で、エクセルへの変換が簡単に行えます。
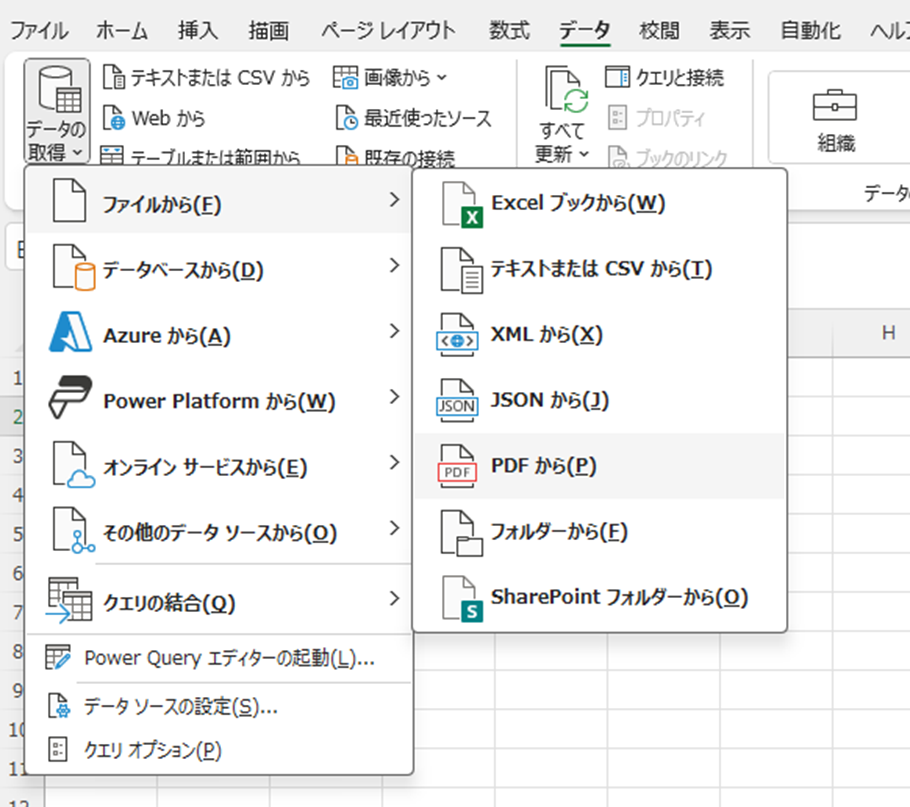
1.データタブの「データの取得」から、PDFを選択
下記のように、データタブの「データの取得」から、ファイル→「PDFファイルから」を選択すると、PDFファイルをエクセル化することができます。
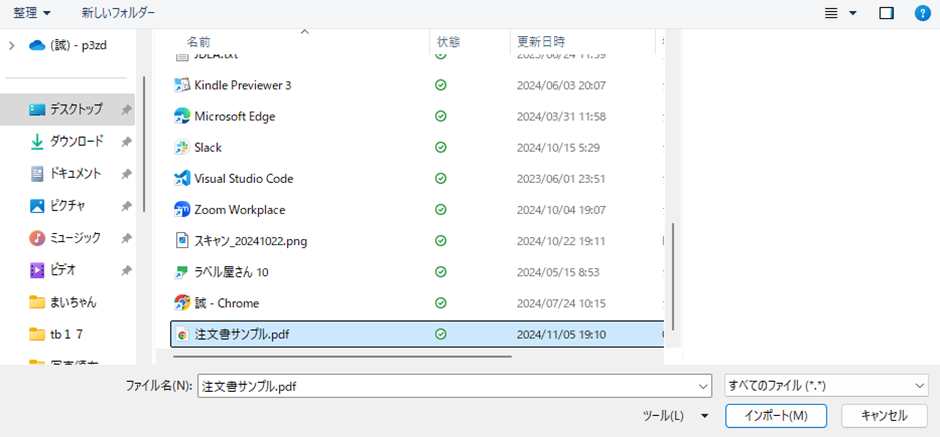
2.PDFファイルを選択します。
PDFファイルを選択する際、右下のフィルタオプションが初期状態では「すべてのファイル」となっており、多くのファイルがある場合、目的のファイルを探すのに時間がかかります。その場合、ファイル名の欄に「*.pdf」と入力すると、PDFファイルだけが表示されるので、簡単に見つけることができます。ファイルを選択したら「インポート」をクリックします。
3.どのテーブルを読み取るのか選択します
テーブルを選択するとプレビュー画面が表示されるので、取り込みたいテーブルを選びます。今回の例では明細部分を取り込みたいので、「Table001」を選択します。テーブルを選択したら、右下の「データ変換」ボタンをクリックします(画像には該当ボタンが映っていませんが…)。
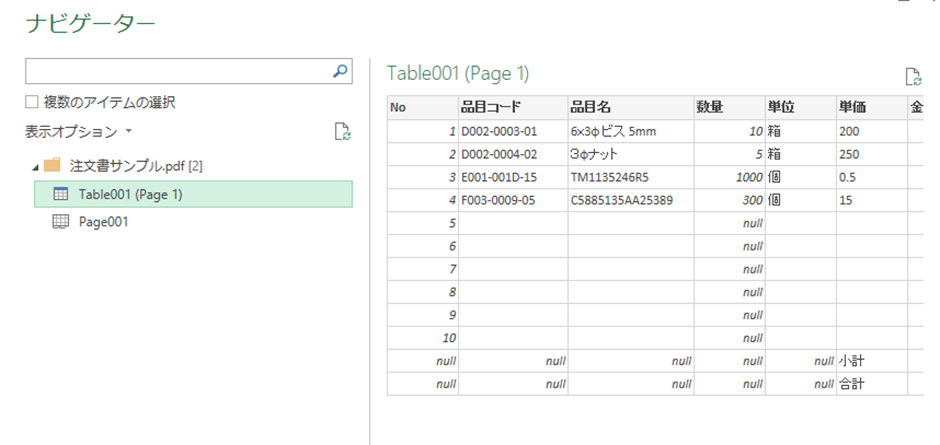
4.PowerQueryでデータを整える
データの取込みをすると、Power Queryが開きます。ここで不要な項目を削除したり、形式を整えたりすることができます。また、関数を使って不要な文字を削除したり、必要な文字を追加するなどの編集も可能です。関数についての詳しい説明は、Microsoft Learnのページをご参照ください。
最後に、左上の「閉じて読み込む」を押すとエクセルに書き込みされます。
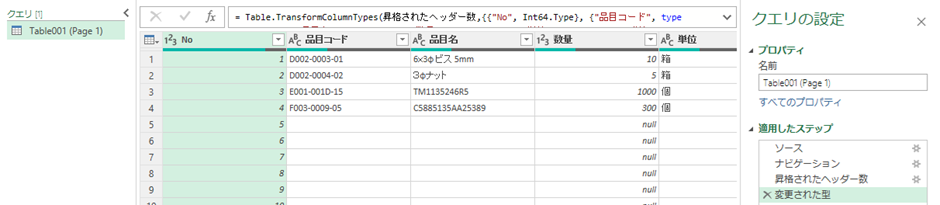
5.エクセル化完了
これで、実際にPDFがエクセルになりました。
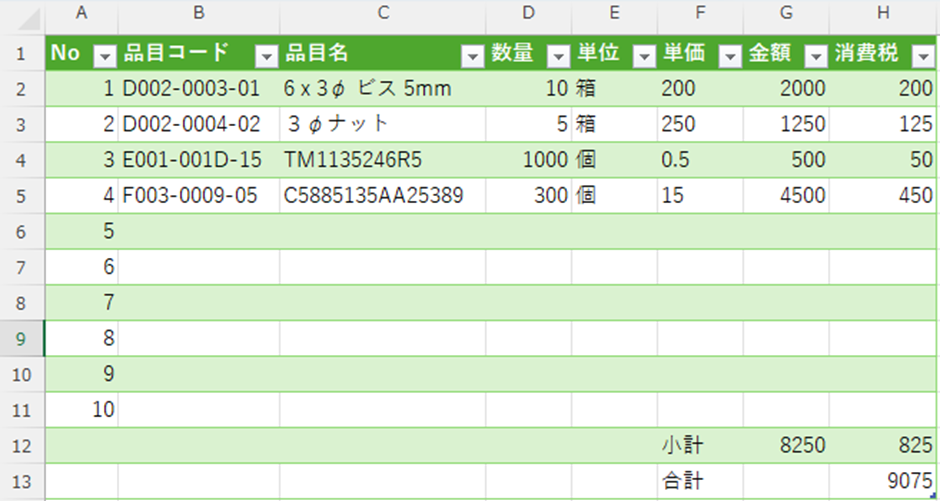
手順をしっかり踏めばエクセル化できますが、操作が多くて手間がかかりますよね。
ただ…実を言うと、この記事、テイク2なんです💦
最初の試みでは、「No」と「品目コード」が一緒になってしまったり、「数量」と「単位」がくっついてしまい、数量が数値ではなく文字列になって集計式が使えなかったりと、いくつかの問題がありました。
コツとして、項目と項目の間にスペースが入るよう、セルの大きさや右寄せ・左寄せなどの配置を意識することが重要です。今回は自分で準備したPDFなので読み取りやすい形式に変更できましたが、ステークホルダーから送られてくるPDFではそのような調整が難しいため、変換後に手動で修正する必要があります。それもまた手間がかかる作業ですね。
無料OCRツールでPDFをエクセルに変換する方法
無料のOCRツールはいくつかありますが、ここでは「LightPDF」を使用してみます。LightPDFはPDFの編集などが行えるツールで、OCR機能も備わっています。クラウドで利用できるため、パソコンにインストールせずにOCR機能を使える点が便利です。
上記URLからサイトにアクセスできます。TOPページが開いたら、少し下にスクロールしてください。下記のようなメニューが出てきますので、ここで左下のOCRを選択します。ファイルの選択画面になるので、PDFファイルを選択した後に出力先を選択します。デフォルトではワード形式になっていますので、エクセル形式に変更しましょう。最後に「OCR」ボタンを押すと、変換されたエクセルファイルがダウンロードできるようになります。

こちらが、ダウンロードしたExcelファイルです。ご覧のように、ページのすべての項目が読み取られており、明細部はきちんと表形式で再現されていますね。

ただ…データとして欲しかった明細部以外も取り込んでしまっています。今回は1ページのPDFで取り込んだので、ヘッダー部とフッター部を1回ずつ削除すれば良いのですが、複数ページにわたるPDFファイルだと、各ページごとにヘッダー部とフッター部が付与されてしまうため、いちいち削除しなければならないのはかなり面倒ですね。
有償OCRツールでの高度なエクセル変換
最後は、シー・システムから提供されているAI JIMY Paperbotを活用して、エクセルに変換してみます。
AI JIMY Paperbotは、RPA機能を実装したAI OCRツールとなりますが、今回はRPA機能は使わず、OCR機能だけで実装してみたいと思います。
1.ワークフローを新規作成する
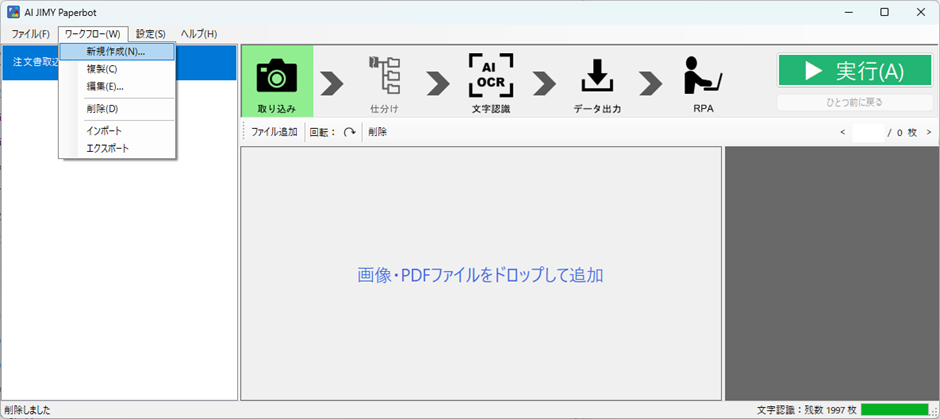
AI JIMY Paperbotを立ち上げたら、メニューのワークフローから新規作成を選択します。
ワークフローとは、PDFファイルの取り込み → 帳票の仕分け(後ほど説明します) → 文字認識 → データ出力 → (今回は利用しませんが)出力されたデータを活用するRPA機能と、一連の作業の流れとなります。
ここでは、「注文書取込み」としてワークフローを設定していきたいと思います。
最初はワークフロー名を決めるだけですので、入力できたら「次へ」を押します。
2.取込み
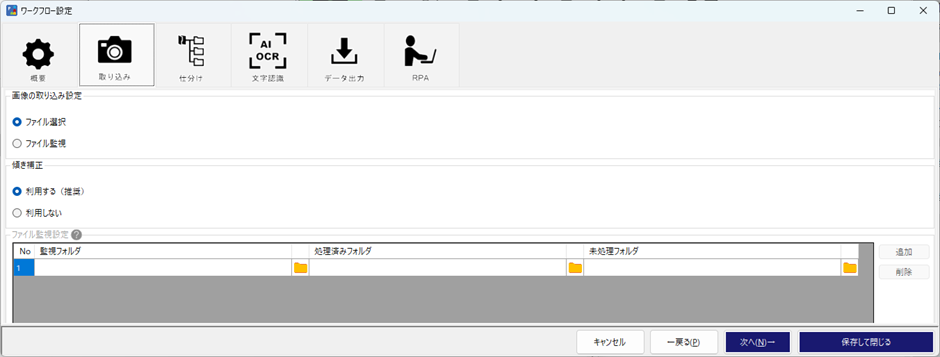
上の段では、PDFファイルの取り込み方法を指定します。
・ファイル選択 … こちらは、指定したファイルを取り込みます。手動実行の場合にオススメ。
・ファイル監視 … こちらは、指定したフォルダにファイルが保存されると実行されます。
今回は、手動実行で大丈夫ですので、「ファイル選択」としておきます。
ファイル監視を指定した場合は、どのフォルダを監視対象フォルダにするのか、一番下のブロックで指定ができます。実行後、正しく処理されたものは処理済みフォルダへ、異常があり処理が正しくされなかったものは未処理フォルダへ移動しますので、それらのフォルダも併せて指定します。
下段は、傾き補正機能を利用する / 利用しないの選択です。
FAXで送られてくる用紙だと、たまに斜めで送られてくるものがあります。それらを正しい向きに補正してくれる機能です。 斜めのままOCRで読み取ると、精度が非常に下がってしまいます。「利用する」が推奨となっておりますので、こちらも、そのまま利用しましょう。
設定が完了したら「次へ」を押します。
3.仕分け
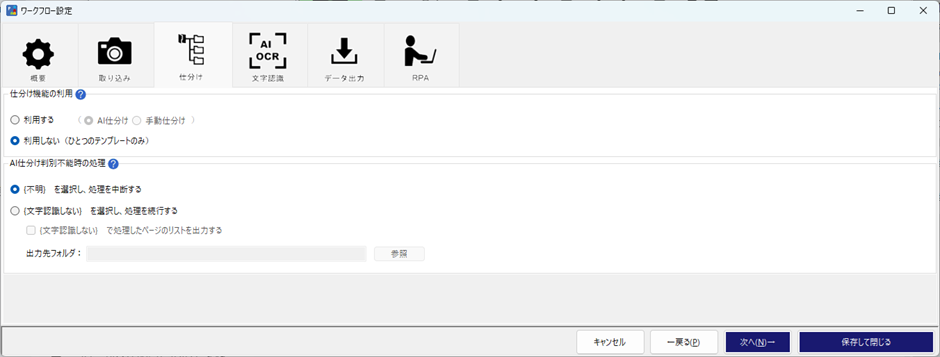
仕分けとは種類が複数ある帳票を、1つのワークフローで処理する際に使う機能になります。例えば、注文書として3種類の帳票レイアウトがあるとき、それぞれでワークフローを作る方法もあります。それぞれでワークフローを作るので、修正が入るとすべてのワークフローで同様の修正が必要になり、手間がかかります。一方で、仕分け機能を使うことで、それらをまとめて1つのワークフローで管理することができるようになり、修正時の手間を大きく削減できます。
ただ、今回は1つの帳票レイアウトしか使いませんので、仕分け機能は「利用しない」を選択してください。下段の「AI仕分け判別不能時の処理」は、仕分けができなかった帳票をどのように処理するのかを指定できます。
・(不明)を選択し、処理を中段する
・(文字認識しない)を選択し、処理を続行する。
4.文字認識
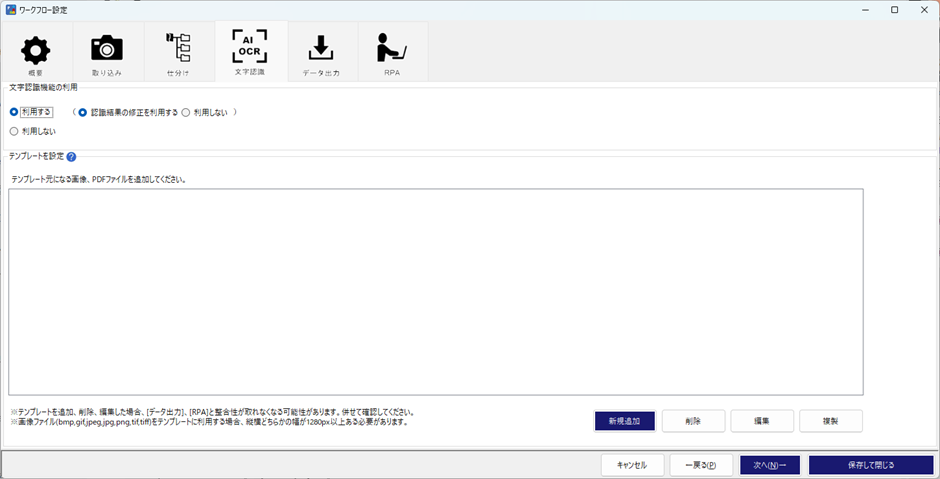
ここでは、実際に帳票レイアウト毎に、読み取る項目を設定します。
まず設定項目として、上段にあるのが「文字認識機能の利用」確認です。
・利用する … OCR機能を利用する場合に設定します。
・認識結果の修正を利用する … OCRを利用する際に、読み取り結果の確認画面を利用する。
・利用しない … OCR機能を利用しない。
今回は、利用する(認識結果の修正を利用する)にチェックを入れます。
テンプレート設定は、帳票レイアウトの設定を指定します。新規追加ボタンを押して、PDFを選択します。選択すると、下記のようにPDF画面が表示されて、どの項目をどのように読むのか設定する画面となります。
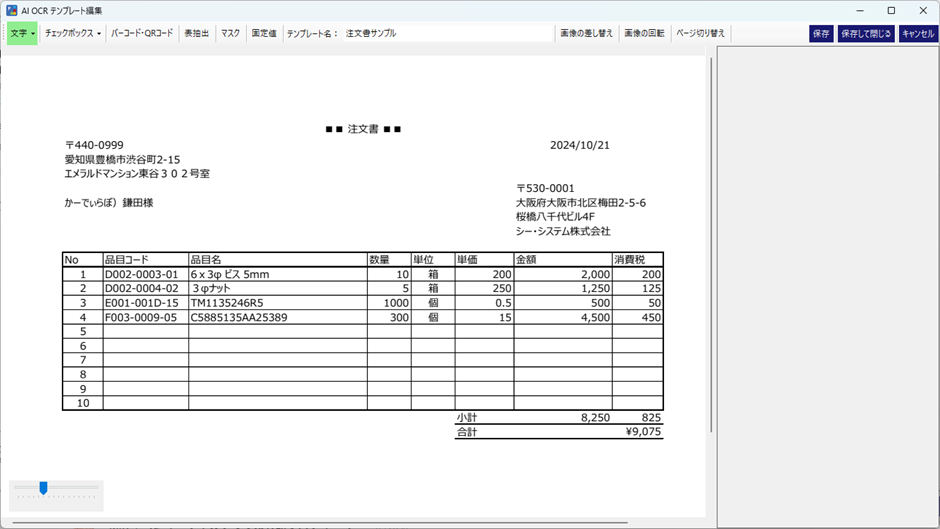
項目毎(文字、チェックボックス、バーコード・QRコードなど)の設定も可能ですが、今回は明細部が欲しいので、表抽出機能を使います。表抽出機能を選択して、下記のように明細部を矩形で囲みます。すると、列毎に項目を指定できるようになるので、順次設定していきます。
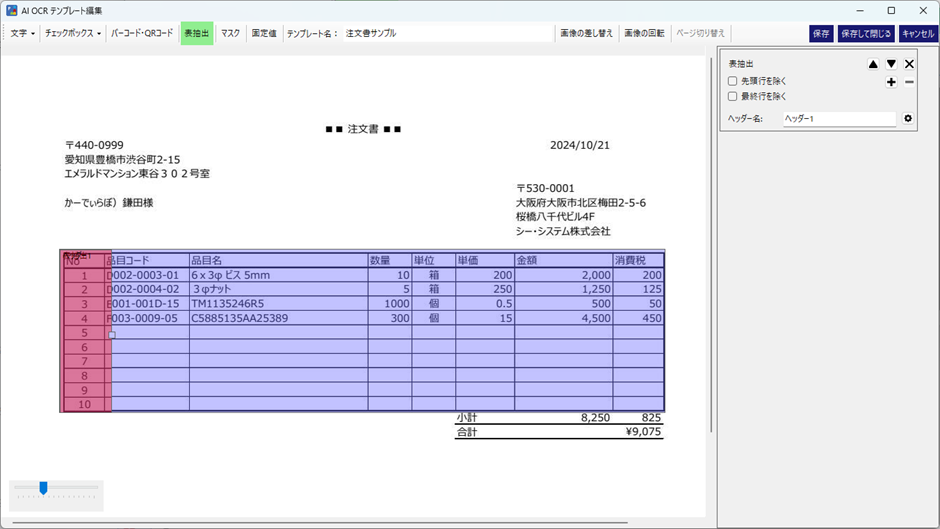
全ての項目を設定します。
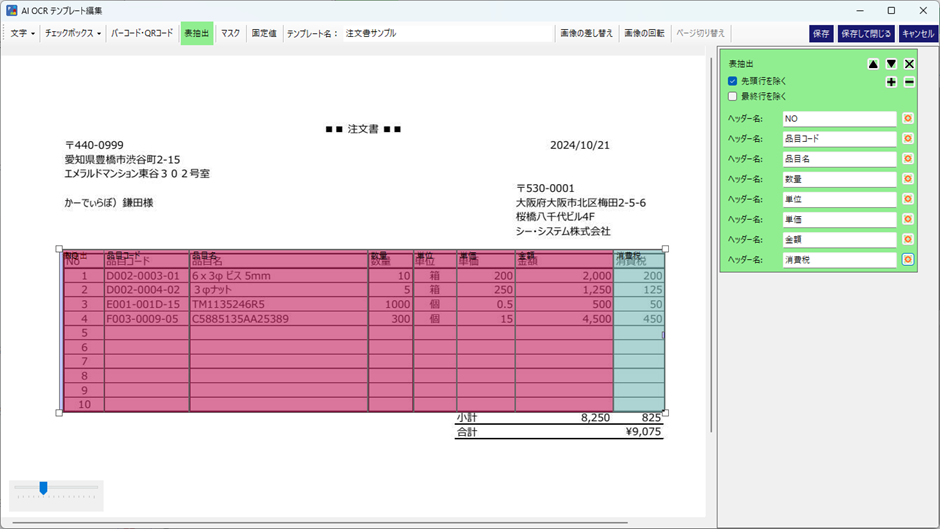
この時、右側上部の「先頭行は除く」にレ点を入れます。これをすることで、先頭行が読み飛ばれるため、データ内に先頭行が含まれなくなります。
また各項目では、読み取る項目が文字 or 数字や、前後の空白を除去する/しない、1行に収まる/収まらないなどの設定値があるので、適切に設定します。
設定が終わったら、「保存して閉じる」を押して、テンプレート編集画面を閉じます。
ここまでできたら「次へ」を押して、データ出力の設定を行います。
5.データ出力
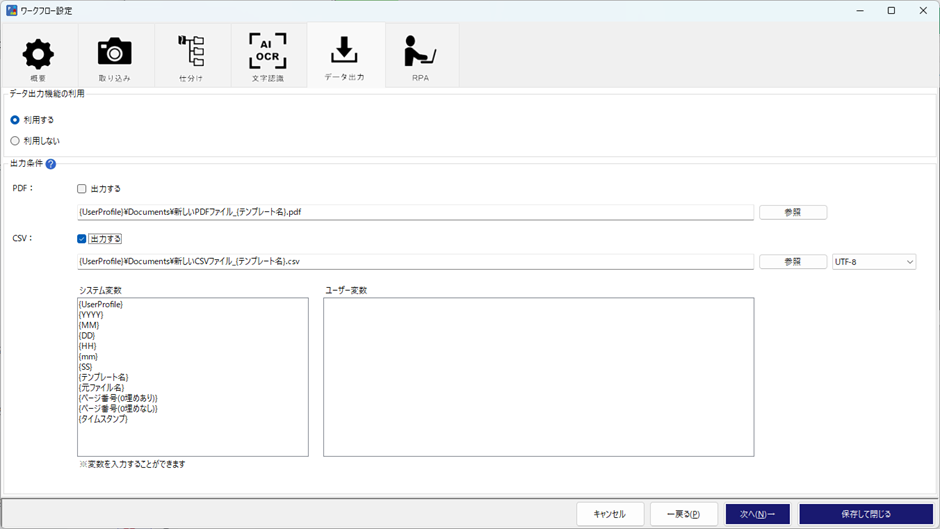
ここでは、読み取った結果を、どのような形式でデータ出力するのかを指定します。
上段はデータ出力機能を利用する/利用しないのフラグです。下段は、データ出力機能を「利用する」とした場合、PDF/CSVのそれぞれのデータ出力先を指定できます。
今回は、PDFのデータをエクセル化したいので、データ出力機能を利用する、に設定します。出力フォルダは任意ですが、チェックはCSVだけで大丈夫です。
ここまで出来たら「保存して閉じる」を押します。
※冒頭述べたように、今回RPA機能は使いませんので、編集画面は閉じてしまって大丈夫です。
エクセル化するための準備が出来たので、作成したワークフローを選択した上で、PDFファイルを選択し、実行ボタンを押します。
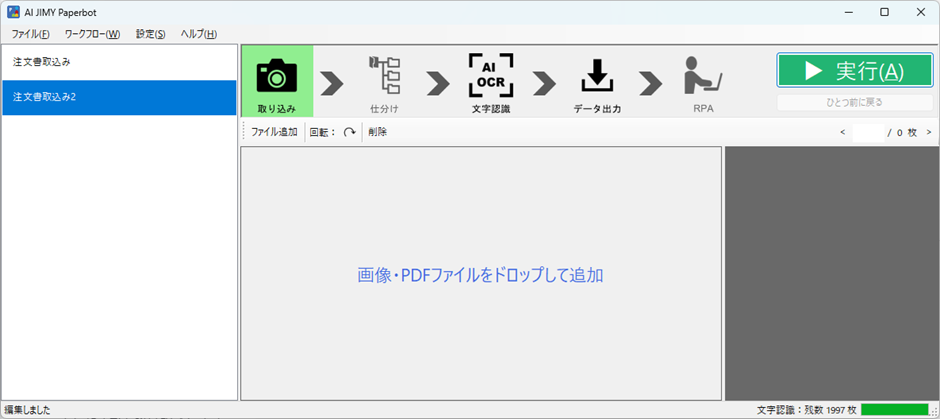
すると、指定したフォルダにCSVファイルが出来ていますので、エクセルで開いています。
下記のようなCSVファイルができましたでしょうか?
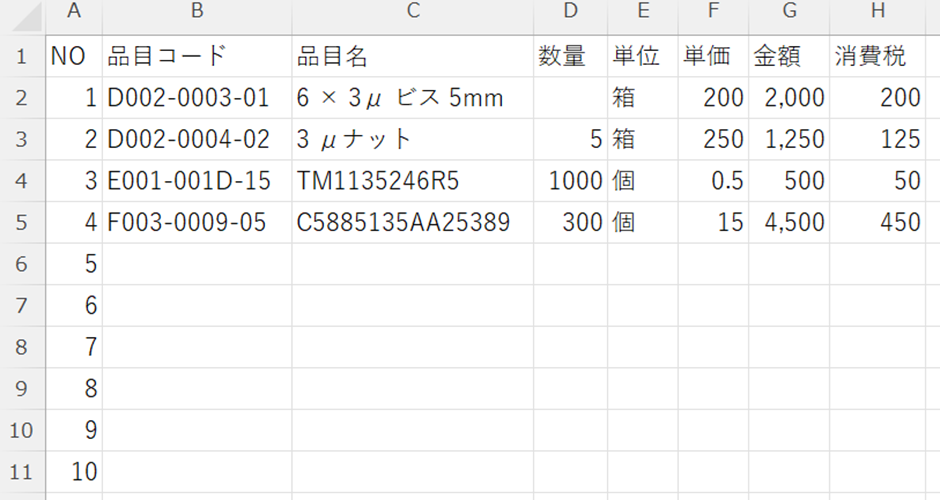
今回はデータのエクセル化までしか行いませんでしたが、AI JIMY Paperbotなら、RPA機能でこのデータを使って基幹システムへのデータ投入まで1つのワークフローで実装ができます(別のRPAツールが必要ありません)ので、非常に便利ですよね。
変換時の注意点とトラブルシューティング
PDFからエクセルに変換する方法をいくつか見てきましたが、どうだったでしょうか?どの方法も、一長一短ありましたので比較表にまとめてみました。
| 手動コピー | エクセル取込み | LightPDF | AI JIMY | |
| 作業時間 ※1 | 多い | 少し多い | 少し多い | 少ない |
| スキル要件 ※2 | 低い | 高い | 低い | 普通 |
| 初期設定の手間 | 低い | 普通 | 低い | 若干多い |
| データ量の制限 | 人手のため上限あり | 上限なし | 上限なし | 上限なし |
| 柔軟性 ※3 | 高い | 低い | 低い | 高い |
| 精度 ※4 | 悪い | 良い | 普通 | 非常に良い |
※1 作業時間には、エクセルへ取り込む時間と、取り込んだ後の調整の時間を含みます。
※2 その作業を実行するために求められるスキルや知識
※3 データを取り込む際に設定できる自由度
※4 OCRとしての精度に、手動作業等によるミスの発生頻度等を考慮したもの
PDFをエクセルに変換するということは、そのデータを活用したいという意図があるかと思います。そのためには、データの正確性が不可欠であり、高い精度が求められます。
ここでいう精度とは、単にOCRの読み取り精度だけでなく、変換後の処理の手間や、面倒さから生じるミスも含まれます。こうした観点から、今回試した方法の中では、有償ツールになりますが「AI JIMY Paperbot」が非常に優秀でした。
今回ご紹介した通り、PDFからエクセルへの変換にはさまざまな方法があり、それぞれにメリットとデメリットがあります。重要なのは、業務の内容やデータの正確性に対する要求に応じて最適な方法を選ぶことです。
無料ツールを試してコストを抑えるのも良いですし、精度を重視して有償ツールを導入するのも一つの手です。ぜひ、ご自身の業務に合ったツールを見つけて、データ活用の効率を高めてください!


