

本記事はAI OCRツール(AI JIMY Paperbot)とPythonを使って
電子帳簿保存法(電帳法)に対応した複数ページあるPDFを文字情報に基づいて
ファイルリネームを自動化する内容を紹介します。
上記記事で行っていた帳票の読み込み時に1ページ目の情報を次ページ以降に手作業でコピー&ペースト
する事によって複数ページの帳票の1ファイルにまとめる方法を紹介していますが
帳票読み込み時に手作業が一部発生していました。
今回一例としてこの手作業を行わずに自動的に複数ページの帳票を
必要情報に基づいてリネームしつつファイルをまとめる方法について解説します。
はじめに
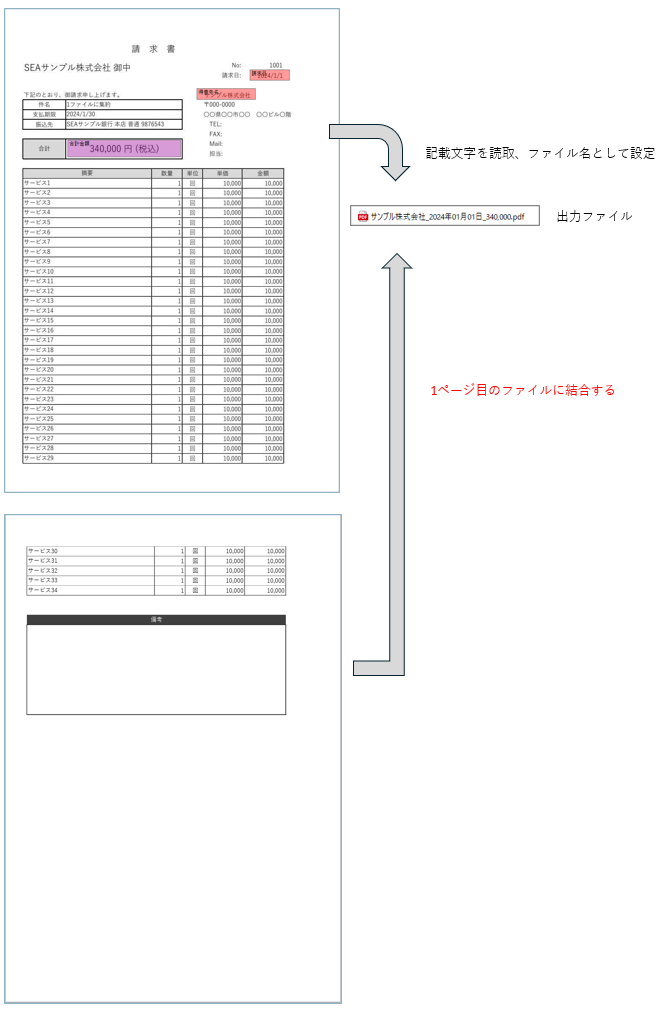
複数ページある帳票の中で1ページ分の情報に基づいて
「帳票種別_請求日_得意先名_合計金額.pdf」
のようなファイルを作る事を想定します。
PDF結合ツール作成
よくPDFの結合で他APIを使用して実現したというケースを見かけますが
有償のライセンスがないと使用できない事が多いです。
今回はPDF結合処理に費用をかけずに実現したい為、
簡単な結合ツールを作成します。
複数ページある帳票をAI OCRツール(AI JIMY Paperbot)から文字認識後
自動リネームすると図のようにページごとにファイルが分割されます。

これを下図のように、
・年月日時分秒
・元ファイル名
・テンプレート名
に基づいてファイル名情報が書いているファイルに結合します。

この結合処理をPythonを用いて自動化する仕組みを作ります。
下記のようなコードを作成しました。
import os
from PyPDF2 import PdfMerger
def merge_pdfs_in_folder(folder_path):
# 結合後のPDFファイルを格納するサブフォルダのパス
output_folder_path = os.path.join(folder_path, 'PDF結合後')
if not os.path.exists(output_folder_path):
os.makedirs(output_folder_path)
# 結合前のPDFファイルを格納するサブフォルダのパス
original_folder_path = os.path.join(folder_path, '結合前元データ')
if not os.path.exists(original_folder_path):
os.makedirs(original_folder_path)
# ファイル名を辞書でグループ化
pdf_groups = {}
for filename in os.listdir(folder_path):
if filename.endswith('.pdf'):
parts = filename.split('_')
timestamp_docname = '_'.join(parts[:2]) # 最初の2つの部分を「年月日時分秒_書類名」として取得
unique_identifier = '_'.join(parts[2:]) # 残りの部分を「*****」として取得
if timestamp_docname not in pdf_groups:
pdf_groups[timestamp_docname] = {'base': None, 'others': []}
# 「{」および「}」が含まれていないファイルをベースファイルとして保存
if '{' not in filename and '}' not in filename:
pdf_groups[timestamp_docname]['base'] = os.path.join(folder_path, filename)
else:
pdf_groups[timestamp_docname]['others'].append(os.path.join(folder_path, filename))
# グループ化したファイルを結合
for timestamp_docname, files in pdf_groups.items():
base_file = files['base']
other_files = files['others']
if base_file is None:
print(f'Base file for {timestamp_docname} not found, skipping.')
continue
merger = PdfMerger()
merger.append(base_file)
for pdf in other_files:
merger.append(pdf)
# ベースファイルのファイル名から出力ファイル名を生成
base_filename = os.path.basename(base_file)
output_filename = '_'.join(base_filename.split('_')[2:])
output_path = os.path.join(output_folder_path, output_filename)
# 同じファイル名がある場合に番号を付ける
base, ext = os.path.splitext(output_filename)
counter = 1
while os.path.exists(output_path):
output_filename = f"{base}({counter}){ext}"
output_path = os.path.join(output_folder_path, output_filename)
counter += 1
merger.write(output_path)
merger.close()
print(f'Merged {timestamp_docname} into {output_path}')
# 結合後、元のファイルを「結合前元データ」に移動
files_to_move = [base_file] + other_files
for file in files_to_move:
new_location = os.path.join(original_folder_path, os.path.basename(file))
os.rename(file, new_location)
print(f'Moved {file} to {new_location}')
# ユーザーにフォルダパスを入力してもらう
folder_path = input("結合したいPDFファイルがあるフォルダのパスを入力してください: ")
merge_pdfs_in_folder(folder_path)今回はAI OCRツールAI OCRツール(AI JIMY Paperbot)を用いますのでファイル名を
「PDF結合_AIJIMY用」としました。

仕分け設定(AI JIMY Paperbot)
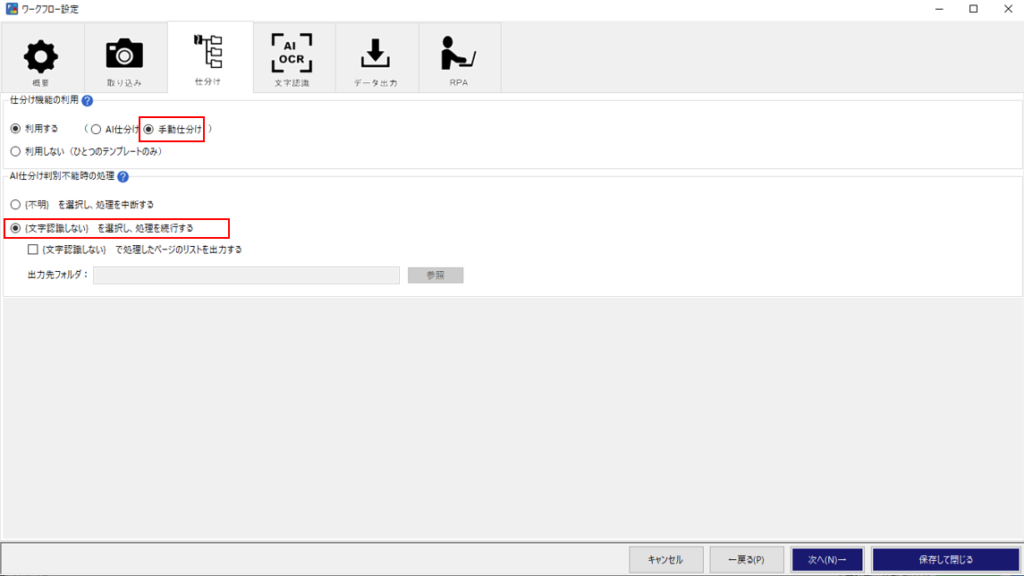
ワークフロー設定>仕分け
画面にて下記2項目を設定する。
①仕分け機能の利用→利用する(手動仕分け)
※文字認識しないページが安定して{文字認識しない}になるようであればAI仕分けに切り替えても良い
②AI仕分け判別不能時の処理→{文字認識しない}を選択し、処理を続行する
を設定します。
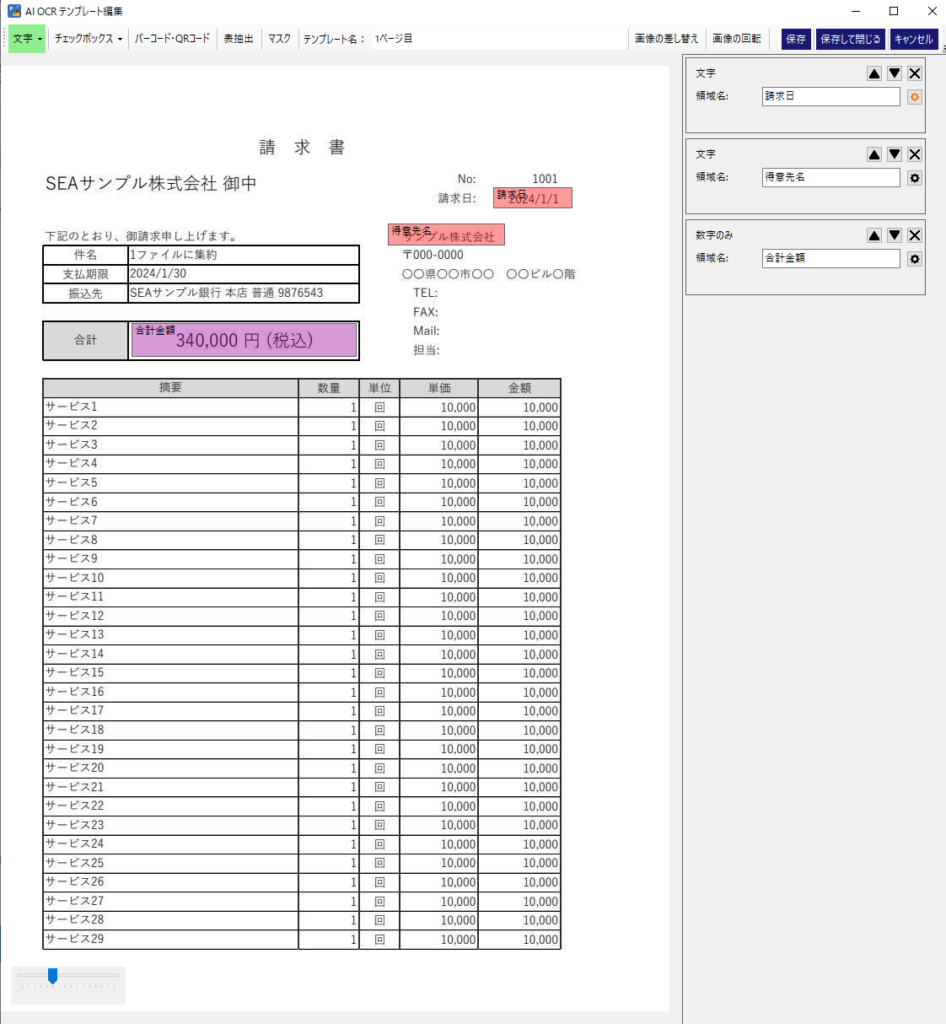
情報取得用テンプレート作成(AI JIMY Paperbot)
通常のテンプレート通り任意で領域設定する。
今回は例として、「請求日_得意先名_合計金額.pdf」で保存を想定しているので、
・請求日
・得意先名
・合計金額
の領域を設定します。
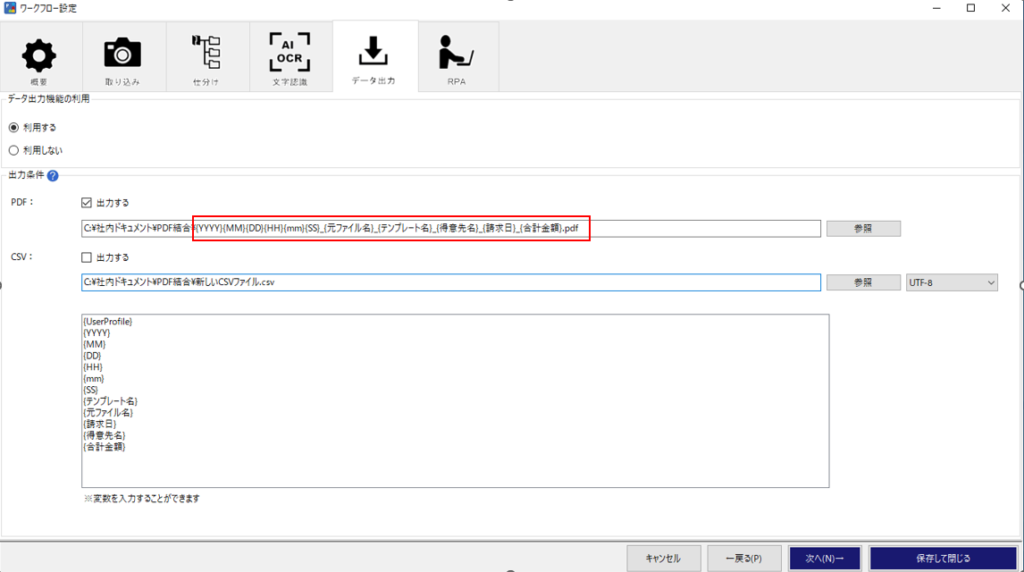
ファイル名設定(AI JIMY Paperbot)
データ出力設定でPDFファイルの保存先、ファイル名を設定します。
今回の例であれば、
「任意のパス\{YYYY}{MM}{DD}{HH}{mm}{SS}_{元ファイル名}_{テンプレート名}_{得意先名}_{請求日}_{合計金額}.pdf」のように設定します。
※「任意のパス\{YYYY}{MM}{DD}{HH}{mm}{SS}_{元ファイル名}_{テンプレート名}_」の所は後処理で使用しますので必ず入れる。
文字認識実行
実行すると1ファイルに2ページ以上が含まれたファイルが分割されて生成されます。
【生成ファイル】
PDF結合
ファイル実行
「PDF結合_AIJIMY用.py」 を実行します。
フォルダパス入力
赤枠のようにAI JIMY Paperbotから出力されたPDFが保管されているパスを入力し、
Enterを押します。

出力結果
実行したフォルダに下記フォルダが生成されます。

PDF結合後フォルダ内
図のようにリネームされてかつ、分割されたページが結合された状態で保存されます。
結合前元データフォルダ内
図のように結合前の元データをそのまま移動されています。

さいごに
今回は電子帳簿保存法に対応した複数ページあるファイルで1ページ分の情報に基づいてリネームしつつ
ファイルを結合する事ができました。
複数ページあるファイルを締日付近等に大量に処理しないといけないといった特殊なケースですが
利用シーンがある方についてはPDFファイルを
に処理を投げて結合ツールを実行するだけで完結するので
作業時間が大幅に削減されますのでぜひお試しください。

AI JIMY Paperbotを利用するメリット
OCRに生成AIとRPAを搭載 一つのツールでデータ入力作業を完結
画像の取り込みから取引先ごとの仕分け、手書き文字の認識、テキストデータの出力、業務システムへのデータ入力まで、一連の作業をAI JIMY Paperbotひとつで自動化できます。
無料で誰でもカンタンに使用可能
AI JIMY Paperbotは特別な技術知識は不要で、マウスだけの直感的な操作が可能です。RPAツールとの連携や専門知識が必要なAPIなどの開発作業は必要ありません。無料で利用開始できますので、カンタンに試すことができます。
自動でファイル名を変換できるリネーム機能
リアルタイム処理を行い、任意で電子帳簿保存法の改正にも対応したファイル名に自動で変換可能です。
AI類似変換で社内のマスタと連携し、文字認識が向上
日本語の認識は、手書きも含めてかなり高い精度で変換できます。間違いやすい商品名などの固有名詞は、あらかじめAI JIMY Paperbotに登録しておくことでさらに認識率が向上します。
多様な業務で活用
さまざまな業務で使用が可能です。FAXの受注入力、請求書の集計、手書きアンケートや申込書のデータ入力、作業日報のデジタルデータ化など多岐にわたる業務プロセスをサポートします。


