

この記事で分かること: PDFのOCR処理で失敗しないための30の実践的チェックポイント、前処理・後処理の最適化方法、システム連携の注意点
はじめに:なぜOCR導入は失敗するのか?
PDFをOCRで文字起こしする作業は、一見シンプルに見えます。「文字が認識できれば良い」と考えがちですが、実務レベルでは単なる文字認識率だけでは不十分なのです。他にも検討すべき事項があります。30選ということでまとめましたので、是非ご確認ください。
特にOCR導入で企業が直面する3大課題
❌ 失敗パターン1: 文字認識率99%なのに業務で使えない
→ 理由:住所や商品名の表記揺れを吸収できず、システム入力で再作業が発生
❌ 失敗パターン2: FAXや手書き帳票で精度が激減
→ 理由:前処理(画像補正)が弱く、ノイズや傾きに対応できない
❌ 失敗パターン3: 導入後に全体のフローと連携できず、運用コストが増大
→ 理由:エラー監視やデータ修正に人手がかかり、効率化につながらない
実際には、認識前の前処理、認識後の後処理、システム連携、セキュリティ、データ変換など、多数の観点をクリアしなければ業務に耐える品質にはなりません。
💡 重要: AI OCRの識字率は100%に達しておらず、最大でも99.97%程度。残り0.03%のエラーが業務の致命傷になることもあります。
本記事では、PDFテキスト化でありがちな落とし穴を踏まえながら、絶対に押さえておくべき30のポイントを体系的にまとめました。
【図解案①】OCR処理の全体フロー
まずは、気になるOCRのエンジンからまとめますので、全体のフローは前後しますが、お許しください。
┌─────────────┐
│ PDF入力 │
│ (原本画像) │
└──────┬──────┘
│
▼
┌─────────────────┐
│ 前処理(画像処理) │ ← ポイント6~10
│ ・ノイズ除去 │
│ ・傾き補正 │
│ ・コントラスト調整 │
└──────┬──────────┘
│
▼
┌─────────────────┐
│ OCR認識エンジン │ ← ポイント1~5
│ ・文字認識 │
│ ・レイアウト解析 │
└──────┬──────────┘
│
▼
┌─────────────────┐
│ 後処理(データ整形) │ ← ポイント11~16
│ ・正規化 │
│ ・表記揺れ補正 │
│ ・フォーマット変換 │
└──────┬──────────┘
│
▼
┌─────────────────┐
│ システム連携/保存 │ ← ポイント17~30
│ ・仕分け │
│ ・データ出力 │
└─────────────────┘
1. OCR処理そのものに関するポイント(基礎編)
ポイント1: “文字認識率”だけで良し悪しを判断しない
❗ 最もよくある誤解: 「認識率99%なら十分でしょ?」
現実: 認識率が高くても、業務で利用できる整形データにならなければ意味がありません。
具体例
- ケース1: 商品名は読めても、システムに入力する「商品コード」に変換できない
- ケース2: 住所は認識できるが、「東京都」「東京」「とうきょう」の表記揺れに対応できない
- ケース3: 日付が「令和5年1月10日」「2023/1/10」とバラバラで、統一できない
重要指標
文字認識率だけでなく、以下も評価すべきです:
- 項目抽出精度: 必要な項目(金額、日付、顧客名など)を正しく取り出せるか
- データ変換精度: システムが求める形式に変換できるか
- 表記揺れ吸収率: 同じ意味の異なる表記を統一できるか
📊 調査データ: AI OCR導入企業の約40%が「認識率は高いが実務で使いにくい」と回答(出典)
ポイント2: PDFの向き自動判定ができるか
裏向き・横向き・逆さまスキャンは、現場で頻繁に起こる問題です。
✅ 必須機能: 自動向き補正(Auto-Rotation)
- 0度/90度/180度/270度の自動判定
- ページごとに向きが異なる複数ページPDFへの対応
- 判定失敗時の手動補正機能
向き補正が弱いOCRは、後作業が激増します。1,000枚の帳票のうち100枚が逆さまだと、手作業で直すだけで数時間のロスが発生します。
ポイント3: 手書き・印刷文字の双方に対応しているか
特に注文書・申込書・アンケートでは手書きが混ざるため、OCRの性能差が顕著に出ます。
AI OCRと従来型OCRの違い
| 項目 | 従来型OCR | AI OCR |
|---|---|---|
| 印刷文字 | ◎ 高精度 | ◎ 高精度 |
| 手書き文字 | △ 50~70% | ◯ 80~95% |
| 崩し字 | × 認識不可 | △ 部分対応 |
| 学習機能 | × なし | ◎ あり |
💡 選定ポイント: 帳票の20%以上に手書きが含まれる場合は、AI OCR必須
ポイント4: 低画質・FAXPDFへの耐性
FAX由来の汚れ・ノイズ・低解像度・かすれは、OCR精度を大きく落とします。
⚠️ FAXの3大障害
- 砂ノイズ: 背景の黒い点々
- 低解像度: 200dpi以下でぼやける
- 線のかすれ: インク切れや紙質の問題
対策
- 前処理の強化(ノイズ除去、解像度補完)が重要
- FAX専用のOCRエンジンを選ぶ
- 受信側でFAX解像度を300dpi以上に設定
ポイント5: 図版・表形式に強いか
帳票の表組みを正しく理解できないOCRは、項目抽出の精度が極端に低くなります。
✅ チェック項目
- 罫線の検出精度
- セル結合への対応
- 縦書き/横書き混在への対応
- 複数カラムレイアウトの解析
特に請求書・見積書・発注書は表形式が多いため、この機能は必須です。
OCRエンジンの選択フローチャート
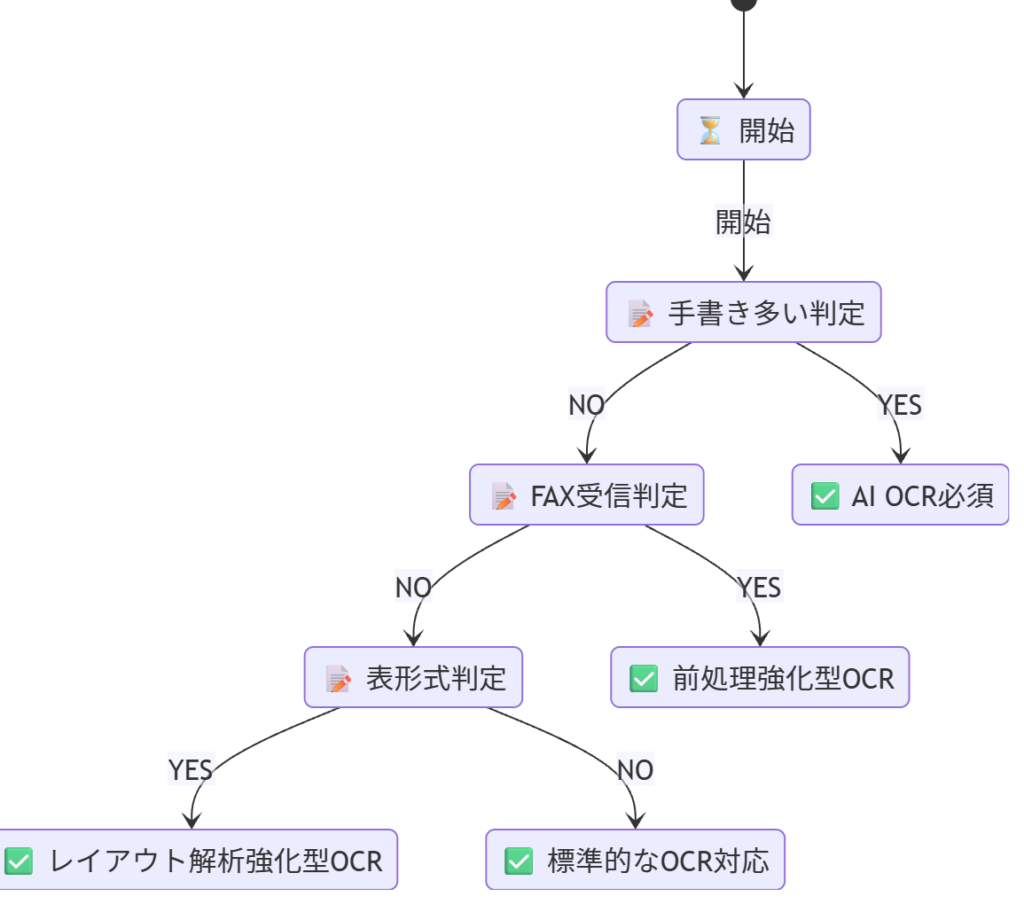
2. OCR前処理(画像処理)の重要ポイント
前処理はOCR精度を左右する最重要工程です。どれだけ優秀なOCRエンジンでも、画像が汚ければ認識できません。
ポイント6: ノイズ除去が強いか
FAXの砂ノイズや黒つぶれをどこまで除去できるかが鍵です。
主なノイズ除去技術
- メディアンフィルタ: 孤立ノイズの除去
- モルフォロジー演算: 小さな黒点の削除
- 適応的二値化: 背景の濃淡に応じた閾値調整
- エッジ保存平滑化: 文字の輪郭を保ちながらノイズ除去
🔧 技術情報: Pythonの
OpenCVライブラリでは、cv2.fastNlMeansDenoising()で効果的なノイズ除去が可能(参考)
ポイント7: 傾き補正(Deskew)ができるか
数度の傾きでOCR認識精度が急落するため、傾き補正は必須です。
傾きによる認識率の低下
| 傾き角度 | 認識率への影響 |
|---|---|
| 0~1度 | ほぼ影響なし |
| 2~3度 | 5~10%低下 |
| 5度以上 | 20~50%低下 |
⚠️ 注意: スキャナーで斜めにセットされるだけで、OCR精度が半減することも
対策
- ハフ変換による自動傾き検出
- 文字列の角度解析
- 画像回転処理(バイリニア補間)
ポイント8: コントラスト調整
薄い文字が潰れないように最適化する機能です。
効果的な手法
- ヒストグラム均等化: 明暗差を強調
- CLAHE(Contrast Limited Adaptive Histogram Equalization): 局所的なコントラスト調整
- ガンマ補正: 全体の明るさ調整
💡 実務Tips: コピー機で何度もコピーされた書類は、コントラストが弱くなっているため要注意
ポイント9: 解像度補完(アップスケール)
低解像度PDFを読み取れるOCRは強力です。
推奨解像度
- 最低ライン: 200dpi
- 推奨: 300dpi以上
- 理想: 600dpi(細かい文字も認識可能)
アップスケール技術
- バイキュービック補間: 滑らかな拡大
- Super Resolution(超解像): AIによる画質向上
- エッジ強調: 文字の輪郭をクリアに
ポイント10: 位置合わせ(レイアウト補正)
位置指定型OCRの場合、縮尺ズレ補正ができないと致命的です。
位置指定型OCRとは
帳票の「この座標から文字を読み取る」と指定する方式。定型帳票では高精度ですが、わずかなズレで読み取り位置が狂います。
⚠️ よくある失敗例
- スキャン時の用紙の置き方で数mmズレる
- FAX受信時に縦横比が変わる
- コピー機の拡大/縮小設定でサイズが変わる
対策
- テンプレートマッチングによる自動位置合わせ
- アンカーポイント(基準点)の設定
- AI OCRの項目認識機能を活用
【図解案③】前処理の効果比較
[Before] [After]
原画像 ノイズ除去後
━━━━━━━━━━━━ ━━━━━━━━━━━━
ザラザラ クリア
薄い文字 濃い文字
傾き3度 傾き0度
200dpi 300dpi相当
━━━━━━━━━━━━ ━━━━━━━━━━━━
認識率: 70% 認識率: 95%
3. OCR後処理(文字データ整形)の超重要ポイント
OCRで認識した文字は、そのままでは業務に使えません。後処理で「使えるデータ」に変換する必要があります。
ポイント11: 住所の正規化
住所の表記揺れは、システム入力や顧客マスター照合で問題になります。
よくある表記揺れ
例1: 大阪府の場合
- 「大阪府大阪市北区梅田」
- 「大阪市北区梅田1-1-1」
- 「梅田1丁目」
- 「大阪府大阪市北区梅田一丁目」
例2: 番地の表記
- 「1-2-3」
- 「1丁目2番3号」
- 「一丁目二番三号」
正規化技術
- 郵便番号辞書: 郵便番号から正式住所を補完
- 都道府県補完: 省略された都道府県名を追加
- 丁目・番地の統一: 「1-2-3」形式に統一
- 全角/半角の統一: 数字を半角に統一
🔧 実装Tips: GoogleのJapan Postal Code APIや、住所正規化ライブラリが便利
カンタンに実装するにはAI JIMY Converterがおススメ
ポイント12: 日付フォーマット変換
日付の表記揺れは、システム入力やソート処理で大きな問題になります。
日付表記の多様性
| 元の表記 | 変換後(システム用) |
|---|---|
| 令和5年1月10日 | 2023-01-10 |
| 2023/1/10 | 2023-01-10 |
| 1/10 | 2023-01-10(年補完) |
| R5.1.10 | 2023-01-10 |
| 2023年01月10日 | 2023-01-10 |
✅ 必須機能
- 和暦→西暦変換
- 年月日の区切り文字統一
- ゼロパディング(01月、02日)
- 年省略時の補完(直近年を仮定)
ポイント13: 商品名の揺れ補正(同義語辞書)
商品名の表記揺れを、共通の商品コードに変換できるかが重要です。
具体例
例1: トナーの場合
- 「トナー黒」
- 「トナー ブラック」
- 「黒トナー」
- 「Black Toner」
→ すべて商品コード「TNR-BK-001」に変換
例2: サイズ表記
- 「Lサイズ」
- 「L」
- 「Large」
- 「ラージ」
→ すべて「SIZE-L」に統一
実装方法
- 同義語辞書の構築: 表記揺れと正式名称のマッピング
- 部分一致検索: 前方一致・後方一致・あいまい検索
- 機械学習による推定: 過去データから自動学習
ポイント14: 全角・半角・記号揺れの補正
ハイフン・長音・スペース揺れをどこまで吸収できるかが重要です。
よくある揺れパターン
# ハイフン・マイナス記号の揺れ
「-」(半角ハイフン)
「ー」(全角長音)
「‐」(全角ハイフン)
「−」(全角マイナス)
「–」(ENダッシュ)
「—」(EMダッシュ)
# スペースの揺れ
「 」(全角スペース)
「 」(半角スペース)
「」(スペースなし)
# カッコの揺れ
「(」(半角)
「(」(全角)
✅ 推奨対応
- 全角英数字 → 半角英数字
- 半角カナ → 全角カナ
- 記号類の統一ルール設定
- 余分なスペースの削除
ポイント15: UTF-8 / Shift-JIS の使い分け
特に基幹システムがSJISしか通らないケースでは非常に重要です。
文字コードの選択基準
| システム | 推奨文字コード | 理由 |
|---|---|---|
| 基幹システム(旧型) | Shift_JIS | 古いシステムはSJIS固定が多い |
| Webシステム | UTF-8 | 現代の標準、多言語対応 |
| CSVファイル | BOM付きUTF-8 | Excelで文字化けしない |
⚠️ 注意: 「髙」「﨑」などの異体字は、Shift_JISで文字化けする可能性あり
ポイント16: キーワード抽出の精度
文章の中から必要な情報だけを抜き出せるかが重要です。
活用例
例1: 備考欄から納期を抽出
備考欄: 「至急対応願います。納期は2月15日厳守でお願いします。」
→ 抽出結果: 「2025-02-15」
例2: 金額の抽出
本文: 「合計金額は¥123,456-(税込)となります。」
→ 抽出結果: 「123456」(数値型)
技術手法
- 正規表現パターンマッチング
- 自然言語処理(NLP)による意味解析
- 固有表現抽出(NER: Named Entity Recognition)
【図解案④】後処理のデータフロー
[OCR認識結果]
┌────────────────────┐
│ 令和5年1月10日 │
│ 大阪市北区梅田1-1 │
│ トナー 黒 ¥5,000 │
└────────┬───────────┘
│
▼
[正規化処理]
┌────────────────────┐
│ 2023-01-10 │ ← 日付変換
│ 大阪府大阪市北区 │ ← 住所補完
│ 梅田1丁目1番 │
│ TNR-BK-001 5000 │ ← 商品コード変換
└────────┬───────────┘
│
▼
[システム入力形式]
{
"date": "2023-01-10",
"address": "大阪府大阪市北区梅田1-1",
"product_code": "TNR-BK-001",
"price": 5000
}
4. PDFの分類・自動仕分けのポイント
複数種類の帳票が混在する場合、自動分類機能は業務効率化の鍵です。
ポイント17: 文書種別の自動判定
注文書・請求書・領収書・見積書などの種類を自動判定できるかがポイントです。
判定手法
- キーワードマッチング: 「請求書」「御見積書」などのタイトルで判定
- レイアウトパターン認識: 罫線の位置や項目配置で判定
- 機械学習による分類: 過去データから学習したAIモデルで判定
メリット
- 手作業での仕分け不要
- 処理ルールの自動適用
- 保存先フォルダの自動振り分け
ポイント18: 複数ページPDFの分割ルール
ページごとに別文書なのか、ひとまとまりなのかを自動判断する機能です。
判定ルール例
# パターン1: タイトル行で分割
各ページの先頭に「注文書」があれば、1ページ=1文書
# パターン2: 空白ページで分割
空白ページを区切りとして文書を分割
# パターン3: ページ番号で判定
「1/3」「2/3」「3/3」があれば、3ページで1文書
ポイント19: 複数フォーマットへの対応力
企業ごとにフォーマットが異なる帳票でも、共通ロジックで仕分けできるかがポイントです。
✅ 理想的な機能
- テンプレート登録不要のAI判定
- 項目名の揺れに対応(「合計金額」「総額」「計」など)
- レイアウト変更への自動追従
5. データ連携・保存関連のポイント
OCR後のデータをどう活用するかが、業務効率化の成否を分けます。
ポイント20: OCR後のデータを外部システムと連携できるか
主な連携先
- 基幹システム(ERP、販売管理、在庫管理)
- 受発注システム(EDI、Web受発注)
- 会計システム(弥生会計、freee、マネーフォワード)
- RPA(UiPath、WinActor、Power Automate)
- データベース(SQL Server、PostgreSQL、MongoDB)
連携方式
| 方式 | 特徴 | 適用場面 |
|---|---|---|
| API連携 | リアルタイム、双方向 | Webシステム |
| Webhook | イベント駆動、自動化 | 通知・トリガー |
| CSVファイル | 汎用性高、バッチ処理 | 基幹システム |
| データベース直接接続 | 高速、大量データ | データ分析 |
💡 重要: API・Webhook対応が鍵。ファイル経由だけでは自動化の限界があります。
ポイント21: PDFファイル名の自動リネーム
OCRで読み取った文字列を利用して、ファイル名を自動的に整理できる機能です。
活用例
# Before
scan001.pdf
scan002.pdf
scan003.pdf
# After
20230110_注文書_ABC商事株式会社.pdf
20230112_請求書_XYZ工業.pdf
20230115_見積書_DEF製作所.pdf
✅ リネームルール設定例
{日付}_{文書種別}_{顧客名}.pdf{顧客コード}_{注文番号}_{処理日}.pdf{部署名}_{年月}_{連番}.pdf
ポイント22: テキストファイル・CSV・JSON など出力形式の柔軟性
後工程の仕様に合わせられるかが重要です。
主な出力形式
| 形式 | 用途 | メリット |
|---|---|---|
| CSV | Excel、基幹システム | 汎用性が高い |
| JSON | WebAPI、プログラム連携 | 構造化データに最適 |
| XML | EDI、レガシーシステム | 業界標準に対応 |
| TXT | 単純なテキスト抽出 | 軽量、シンプル |
| Excel | 人間の確認作業 | 見やすい、編集しやすい |
ポイント23: メタデータ(属性値)の付与
文書種別・顧客ID・日付などを付与して管理しやすくする機能です。
メタデータの活用
Copy{
"file_name": "注文書_ABC商事.pdf",
"document_type": "注文書",
"customer_id": "C12345",
"order_date": "2023-01-10",
"total_amount": 123456,
"processed_date": "2023-01-11 09:30:15",
"ocr_confidence": 0.98
}
メリット
- 高速検索が可能
- 自動仕分けの精度向上
- 監査証跡の記録
6. 安全性・セキュリティに関するポイント
機密文書の扱いは、企業にとって最重要事項です。
ポイント24: クラウドOCRでも”学習しない”か確認
⚠️ 重大リスク: 機密文書がAIモデルの学習データに使われる可能性
確認すべき項目
- 利用規約の確認: 「アップロードデータを学習に使用しない」と明記されているか
- データ保持期間: 処理後すぐに削除されるか
- データ保存場所: どの国のサーバーに保存されるか(GDPR、個人情報保護法対応)
安全なサービス例
- Google Cloud Vision API: 「顧客データを学習に使用しない」と明記
- Azure Computer Vision: 企業向けプランでデータ保護保証
- AWS Textract: プライバシー保護明記
必ず、最新の契約内容をご確認ください。
ポイント25: クライアントアプリで画像処理が可能か
完全クラウド依存だと情報が外部に出てしまうため、クライアント側で前処理できるのは強みです。
✅ 理想的な構成
- クライアント側: 画像の前処理(ノイズ除去、傾き補正)
- クラウド側: OCR認識のみ
- クライアント側: 後処理(データ整形、システム連携)
→ 機密情報の露出を最小化
ポイント26: マスキング機能(黒塗り機能)
個人情報など指定箇所を自動でマスクしてからOCRに送れるかがポイントです。
活用例
# マスキング対象
- マイナンバー
- クレジットカード番号
- 銀行口座番号
- 個人の住所・電話番号
# 方式
- 座標指定マスキング(X:100, Y:200の領域を黒塗り)
- キーワード検出マスキング(「個人番号」の後ろ12桁を自動マスク)
ポイント27: オフライン環境での処理可否
官公庁・金融・医療などではオフラインOCRが必須です。
オフライン対応OCRの選択肢
- オンプレミス型AI OCR: 社内サーバーに設置
- デスクトップアプリ型: PC単体で動作
- エッジデバイス型: 専用端末で処理
7. 運用効率に関するポイント
導入後の運用コストを下げることが、長期的な成功の鍵です。
ポイント28: 自動取り込み(ウォッチフォルダ)
PDFをフォルダに置くだけで、OCR → 仕分け → 出力まで自動化できる機能です。
✅ 自動化の流れ
1. 監視フォルダにPDFを保存
2. 自動的にOCR処理開始
3. 文書種別を自動判定
4. 仕分けルールに従って出力先を決定
5. データをシステムに自動送信
6. 完了通知メール送信
メリット
- 人手ゼロで24時間稼働
- 処理待ち時間ゼロ
- ヒューマンエラー削減
ポイント29: FAX連携(クラウドFAX → OCR)
FAX受信 → 自動OCR → 仕分け → データ出力ができれば、人手ゼロ運用が可能です。
連携例
[クラウドFAX] → [OCR] → [仕分け] → [基幹システム]
│ │ │ │
受信 文字認識 注文書/請求書 自動入力
対応サービス例
- eFax: PDF自動送信機能あり
- BizFAX: OCR連携API提供
- MOVFAX: Webhook対応
ポイント30: 運用ログ・エラー監視
「どのPDFが失敗したか」「何が原因か」を見える化できるかは、運用上欠かせません。
必須ログ項目
- 処理ログ: 処理日時、ファイル名、処理時間
- エラーログ: エラー内容、スタックトレース、再処理可否
- 精度ログ: OCR信頼度スコア、認識成功率
- 監査ログ: 誰が・いつ・何を処理したか
エラー監視の自動化
- Slack/Teams通知: エラー発生時に即座に通知
- ダッシュボード: 処理件数、エラー率をグラフ表示
- 自動リトライ: 一時的なエラーは自動再実行
運用自動化の全体像
┌─────────────┐
│ FAX受信 │
│スキャン投入 │
└──────┬──────┘
│
▼
┌─────────────────┐
│ ウォッチフォルダ │ ← ポイント28
│ 自動監視 │
└──────┬──────────┘
│
▼
┌─────────────────┐
│ OCR処理 │
│ (前処理→認識→後処理) │
└──────┬──────────┘
│
├→ 成功 ──→ [仕分け] → [システム連携]
│
└→ 失敗 ──→ [エラーログ] → [通知] ← ポイント30
まとめ:OCR成功の3大要素
PDFの文字起こし・テキスト化は、単なるOCR精度の問題ではなく、
前処理 → OCR → 後処理 → データ変換 → システム連携 → セキュリティ
という一連のワークフローの最適化が成功のカギです。
特に、実務で求められるのは次の3点です:
成功の3大要素
1️⃣ 認識した文字を業務データへ変換できること
単に「文字が読めた」だけでは不十分。システムが求める形式(商品コード、正規化住所、統一日付など)に変換できることが必須。
2️⃣ 情報の揺れ・表記ブレを吸収できること
「トナー黒」「黒トナー」「ブラックトナー」を同一商品として認識し、後工程で混乱を起こさない仕組みが重要。
3️⃣ 現場で発生する例外(FAX・ズレ・汚れ)に強いこと
理想的な環境でのみ動作するOCRは実務で使えない。ノイズ・傾き・低画質に強い前処理が不可欠。
この30項目をチェックすることで
✅ OCR選定の失敗を防げる
✅ 導入後の再作業を大幅削減できる
✅ 業務効率化の効果を最大化できる
✅ セキュリティリスクを回避できる
✅ 長期的な運用コストを削減できる
最後によくある質問(FAQ)もまとめます
Q1: OCRの認識率は何%が合格ラインですか?
A: 単純な認識率だけでは判断できません。
- 印刷文字のみ: 99%以上が目安
- 手書き混在: 80~90%でも合格(AI-OCR使用)
- FAX文書: 85%以上なら優秀
ただし、業務で必要な項目(金額、日付など)の抽出精度が99%以上あることが実務では重要です。
上記で説明してきたように実務上、必要な認識精度は変わってきます。
Q2: AI OCRと従来型OCRの違いは?
| 項目 | 従来型OCR | AI OCR |
|---|---|---|
| 手書き認識 | △ 50~70% | ◎ 80~95% |
| 学習機能 | × なし | ◎ あり |
| 非定型帳票 | × 苦手 | ◯ 対応可能 |
| 価格 | 安い | 高い |
結論: 手書きが多い、または帳票フォーマットが統一されていない場合は、AI-OCR推奨。
Q3: 無料OCRと有料OCRの違いは?
無料OCRの制限
- 処理枚数制限(月100枚など)
- 商用利用禁止
- サポートなし
- API連携不可
- セキュリティ保証なし
有料OCRのメリット
- 無制限処理
- システム連携可能
- SLA保証あり
- 優先サポート
- セキュリティ対応
結論: 個人利用なら無料、業務利用なら有料推奨。
Q4: FAXのOCR精度を上げるには?
対策5選
- FAX受信の解像度を上げる(300dpi以上)
- ノイズ除去の強いOCRを選ぶ
- クラウドFAXを使う(紙FAXより高画質)
- 送信元に依頼(「Fine」モードで送信してもらう)
- 前処理を強化する(メディアンフィルタなど)
Q5: OCR導入の費用相場は?
| OCRタイプ | 初期費用 | 月額費用 | 従量課金 |
|---|---|---|---|
| クラウドOCR | 0円~ | 1万~50万円 | 1枚10~100円 or 1項目数円 |
| オンプレミス型 | 50万~500万円 | 保守費用 | なし |
| デスクトップ型 | 1万~10万円 | 1万~50万円 | なしが多い |
Q6: OCR導入の期間はどのくらい?
導入スケジュール
- クラウドOCR(簡易): 1週間~1ヶ月
- クラウドOCR(本格): 1~3ヶ月
- オンプレミス型: 3~6ヶ月
内訳
- 要件定義(1~2週間)
- ツール選定・検証(2~4週間)
- システム連携開発(1~2ヶ月)
- テスト・調整(2~4週間)
- 本番稼働・教育(1週間)
関連記事
- 【2025年最新】AI-OCRツール比較15選 | 機能・価格・導入事例
- OCR精度を99%以上に高める前処理テクニック完全ガイド
- 請求書・見積書のOCR自動化で業務時間を80%削減する方法
- FAX OCRの精度を劇的に改善する5つの方法
📌 この記事が役立ったら、ブックマーク・シェアをお願いします!画像やPDFから文字を抽出する仕組み
OCRは、画像やPDFに含まれる文字をデジタルデータとして扱えるように変換する技術です。この仕組みを理解しておくと、どの無料OCRを選ぶべきか、どの場面でAI OCRが力を発揮するのかが明確になります。まずは基礎から押さえておきましょう。
ここまで読んで、めんどくさいなと思った方は下記ツールをご利用ください。

AI JIMY Paperbotを利用するメリット
OCRに生成AIとRPAを搭載 一つのツールでデータ入力作業を完結
画像の取り込みから取引先ごとの仕分け、手書き文字の認識、テキストデータの出力、業務システムへのデータ入力まで、一連の作業をAI JIMY Paperbotひとつで自動化できます。
無料で誰でもカンタンに使用可能
AI JIMY Paperbotは特別な技術知識は不要で、マウスだけの直感的な操作が可能です。RPAツールとの連携や専門知識が必要なAPIなどの開発作業は必要ありません。無料で利用開始できますので、カンタンに試すことができます。
自動でファイル名を変換できるリネーム機能
リアルタイム処理を行い、任意で電子帳簿保存法の改正にも対応したファイル名に自動で変換可能です。
AI類似変換で社内のマスタと連携し、文字認識が向上
日本語の認識は、手書きも含めてかなり高い精度で変換できます。間違いやすい商品名などの固有名詞は、あらかじめAI JIMY Paperbotに登録しておくことでさらに認識率が向上します。
多様な業務で活用
さまざまな業務で使用が可能です。FAXの受注入力、請求書の集計、手書きアンケートや申込書のデータ入力、作業日報のデジタルデータ化など多岐にわたる業務プロセスをサポートします。

